ULISSE: ULtra compact Index for Variable-Length Similarity SEarch in Data Series
Michele Linardi* Themis Palpanas*
*(Lipade, University Paris Descartes)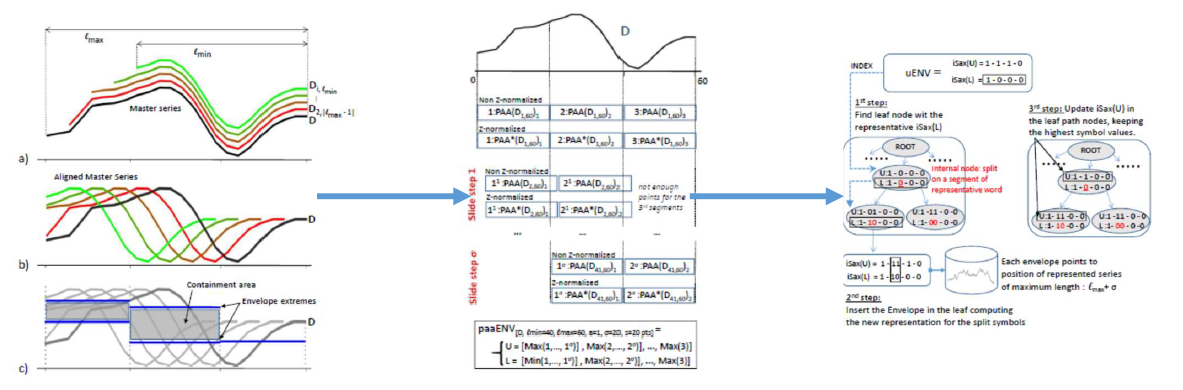
ULISSE: ULtra compact Index for Variable-Length Similarity SEarch in Data SeriesMichele Linardi* Themis Palpanas**(Lipade, University Paris Descartes) |
|
This page is the support page of ULISSE, which mainly complements the experiments conducted, providing the relative materials. You may find the ULISSE article here:ULISSE (VLDB 2018).
Empirical evaluation of our approachIn this following part, we provide the source code of ULISSE (in C). Since the DATASETS used to evaluate our solution are quite big (1GB-100GB), and we do not dispose of such space in the webserver, if you are interested on having those data series collections, please send me an e-mail (michele[dot]linardi[at]orange[dot]fr) and I will provide you a temporary link to download them. Nevertheless, the ULISSE boundle disposes of a synthtetic data generator (Random walk). Please check the README file, you can find it in the source code folder. In this page you can find some information about ASTRO and SEISMIC datasets, we use during our evaluation. Note that the source code file is protected by password. Please contact me at michele[dot]linardi[at]orange[dot]fr. Please note that we compared ULISSE with other approaches suitable for Variable Length Similarity Search in Data Series :
|
|